

Welcome to the latest newsletter prepared by the EAGE A.I. Committee this year. As a group of EAGE members and volunteers they help you navigate the digital world and find the bits that are most relevant to geoscientists.
You are welcome to join EAGE or renew your membership to support the work of the EAGE A.I. Community and access all the benefits offered by the Association.
EAGE Membership Benefits: Join or Renew
Curious to know all EAGE is doing for the digital transformation?
Visit the EAGE Digitalization Hub
![]()
![]() What: Machine Learning Specialization Online Course. An updated and expanded version of Andrew Ng’s 2012 Machine Learning course has been launched. This 3-course specialization will teach you the key concepts and the practical know-how to apply AI techniques to real-world problems. It provides a broad introduction to modern machine learning, including supervised learning (multiple linear regression, logistic regression, neural networks, and decision trees), unsupervised learning (clustering, dimensionality reduction, recommender systems), and some of the best practices used in Silicon Valley for AI and ML innovation.
What: Machine Learning Specialization Online Course. An updated and expanded version of Andrew Ng’s 2012 Machine Learning course has been launched. This 3-course specialization will teach you the key concepts and the practical know-how to apply AI techniques to real-world problems. It provides a broad introduction to modern machine learning, including supervised learning (multiple linear regression, logistic regression, neural networks, and decision trees), unsupervised learning (clustering, dimensionality reduction, recommender systems), and some of the best practices used in Silicon Valley for AI and ML innovation.

![]() Why this is useful: Compared to the original Machine Learning course, the Machine Learning Specialization includes: an expanded list of topics that focus on the most important machine learning concepts (e.g. modern deep learning algorithms, decision trees) and tools (e.g. TensorFlow); assignments and lectures built using Python; a practical advice section on applying machine learning which has been updated significantly based on emerging best practices from the last decade.
Why this is useful: Compared to the original Machine Learning course, the Machine Learning Specialization includes: an expanded list of topics that focus on the most important machine learning concepts (e.g. modern deep learning algorithms, decision trees) and tools (e.g. TensorFlow); assignments and lectures built using Python; a practical advice section on applying machine learning which has been updated significantly based on emerging best practices from the last decade.
Image source: https://www.coursera.org/specializations/machine-learning-introduction?
![]()
![]() What: Upcoming EAGE opportunities
What: Upcoming EAGE opportunities
Sixth EAGE High Performance Computing Workshop:
HPC: A Pathway to Sustainability
This workshop runs from 19-22 September in Milan, Italy. The workshop brings together experts in order to understand state-of-the-art key applications employed in the upstream industry and anticipate what ambitions are enabled by increased computational power. The 3-day workshop will feature both oral presentations and quick lightning talks, panel sessions and keynotes from the leading experts in the industry, as well as plenty of discussion sessions embedded into the program. Check out the workshop overview and registration.
Developing Deep Learning Applications for the Oilfield: From Theory to Real-World Projects
This course is available from 19 September to 19 October 2022. It covers AI history from the 1950s to the AI revolution in 2010s, a review of today’s AI business landscape, basic concepts of Machine Learning presentation of neural networks (NN). It aims for participants to acquire detailed knowledge of Deep Learning, how it works, and in which way it differs from traditional NN that have been used in the industry during the past 30 years. Participants will understand which domains this can be applied to and for what type of applications and the main challenges, difficulties, and pitfalls when developing new AI applications. More information and registration link can be found here.
Introduction to Machine Learning for Geophysical Applications
This course is offered from 15 November to 15 December 2022 with the aim to introduce how Machine Learning (ML) is used in predicting fluids and lithology. The lectures and exercises deal with pre-conditioning the datasets (balancing the input classes, standardization & normalization of data) and applying several methods to classify the data: Bayes, Logistic, Multilayer Perceptron, Support Vector, Nearest Neighbour, AdaBoost, Trees. Non-linear Regression is used to predict porosity. More information and registration link can be found here.
![]()
![]()
What: Geophysics Paper “Seismic impedance inversion based on cycle-consistent generative adversarial network”
It is widely known that seismic impedance inversion can be used to reliably forecast reservoir properties and assist in stratigraphic interpretation. Unfortunately, calculating impedance can be challenging. Although data-driven approaches have shown potential, their application is limited by the lack of labeled data. There aren’t many labeled samples available for inversion due to the high drilling costs and challenges in obtaining well-logging parameters.
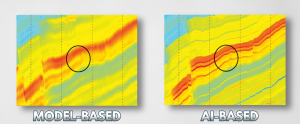
![]() Why this is useful: In this research, the authors propose a method for seismic impedance inversion based on a 1D cycle-consistent generative adversarial network, which is efficient even in the presence of a limited number of labeled samples. In most instances, the suggested method can outperform competing methods, according to testing on synthetic data sets. A higher correlation between the predicted impedance and the true impedance curve is also demonstrated by blind-well studies on real seismic profiles.
Why this is useful: In this research, the authors propose a method for seismic impedance inversion based on a 1D cycle-consistent generative adversarial network, which is efficient even in the presence of a limited number of labeled samples. In most instances, the suggested method can outperform competing methods, according to testing on synthetic data sets. A higher correlation between the predicted impedance and the true impedance curve is also demonstrated by blind-well studies on real seismic profiles.
Credit: Yu-Qing Wang, Qi Wang, Wen Kai-Lu, Qiang Ge, Xin-Fei Yan; https://www.sciencedirect.com/science/article/pii/S1995822621000868
![]()
![]() What: Blog series
What: Blog series
On Normalizing Flows, part 1: basic introduction to Generative Models
This is the first part of a series of blogs written with the intent to introduce the reader on what is a Normalizing Flow, the basics and how it is applied (and can be applied in our industry). The mathematical part will be intentionally kept as readable as possible, with references to more technical landmark articles and Github examples for anyone interested.
Normalizing Flows are a method for creating a Generative Model from data; other approaches include Generative Adversary Networks (GAN) and Variational Auto Encoders (VAE) which are not covered here.
This blog is a very brief and general introduction of what is a Generative Model. Next blog will be a similar introduction on the Normalizing Flows category with respect to underlying basics and how to make them work in principle, followed by actual approaches later on.
Most common Neural Networks used for classification tasks can be categorized as Discriminative Models; their task is restricted to predicting which predetermined type a new data item falls under (and can be very good at this). This is done either purely deterministic (pair a data item with a class, as point value), or including probability (provide the probability of all classes, selecting the ‘best’ one based on highest probability); estimating the P(Y = y) for all of the classes given a data point X = x.
Another common task is regression, where Y represents the basic parameters of the function to be estimated from X (slope and intercept for linear, etc.). This can also include probability (for example Normal distribution around the best fit line, expressed in terms of mean and standard deviation which can vary with each X = x value).
On the other hand, Generative Models are a category that is based on the principle that all data x in a set X come from an underlying distribution P(X) or P(X, Y) which encompasses the entire essence / nature of the mechanism that produced the data / observations set X and can be used to create (generate) new x instances. In a nutshell, P(X) is a (probabilistic) representation of the system that produces the data. Note that Discriminative Models do not analyze the data structure, merely discover enough indications to help divide the data into their user determined classes.
A simple example of a Generative Model is coin tossing, represented by a Bernoulli distribution, where the parameter p is determined through N throws (also called a frequentist type experiment), and the model (just the value 0 < p < 1) can then be used to generate new random numbers 0 ‘tail’ or 1 ‘head’ that simulate new coin tosses.
This principle is also applied to more complicated cases such as sound, images, complex biochemical compound studies where the distributions are highly dimensional as well as highly complex within these dimensions (e.g. multi modal, fat tails, which express the ‘nature of the beast’ in question).
Some important notes:
- Generative Model networks do not need labels, in principle unsupervised; if a set of targets Y are included, a joint probability distribution P(X, Y) is used
- In principle no need for splitting example data X into training, validation, test data; the whole set can and should be used for finding the distribution (modeling through the whole data space)
- Testing is done by sampling from the model; the closer the distribution is to the ‘true distribution’ (the ‘real’ mechanism that generated the data), the better resemblance is
- They work well with large (relatively; still need some preprocessing) unstructured data (I would prefer to call it ‘loosely structured’)
- The size of the network representing P(X) is far smaller than the dataset X, it’s parameters representing the entire set X. This is called ‘amortization’.
- Upon training, a Generative Model can be used to run classification and/or regression as required
Applications include sophisticated denoising, filling missing data (‘inpainting’), enhancing resolution, etc.
Generative Model type networks that approximate the true distribution (generally impossible to capture in any form of closed mathematical representation) are far more complex to develop compared to the more classical Neural Networks, in terms of theoretical background as well as implementation and operating.
They are an area of extensive ongoing research and particularly tremendous results and potential have been shown in recent years.
Overall it is important to note that trying to fit an overly simple distribution to a real data case will effectively remove important information and produce blurry or even downright incorrect and misleading results. Sufficiently detailed ‘expressive’ approximation is therefore essential.
Apart from being very powerful, and able to capture increasingly deeper context and subtle interrelations, Generative Models are also considered more interpretable and can include domain knowledge in their design.
Building them requires sufficient understanding and proficiency in probability (distributions, Bayes theorem, KL divergence, ELBO, etc.), linear algebra, calculus (i.e. Jacobians, bijectors), etc. In fact, the same applies to reading most of the technical (landmark) papers, some of which will be referred to in future blogs.
I point your attention to the below, up to ‘Three approaches to generative models’ (a bit dated but clear) for a more illustrated quick explanation on Generative Models:
https://openai.com/blog/generative-models/
Lastly, I point your attention to a link that in my view describes Bayes Theorem and Bayesian Inference (which is one of the principal formalisms underpinning probabilistic workflows) quite clearly, including most of the terminology used:
https://towardsdatascience.com/how-to-use-bayesian-inference-for-predictions-in-python-4de5d0bc84f3
Credit: Jan H van de Mortel
![]()
Discover EAGE Learning Resources on A.I. and machine learning
Sixth EAGE High Performance Computing Workshop
This newsletter is edited by the EAGE A.I. Committee.
| Name | Company / Institution | Country |
|---|---|---|
| Anna Dubovik | WAIW | United Arab Emirates |
| Jan H. van de Mortel | Independent | Netherlands |
| Jing Sun | TU Delft | Netherlands |
| Julio Cárdenas | Géolithe | France |
| George Ghon | Capgemini | Norway |
| Lukas Mosser | Aker BP | Norway |
| Oleg Ovcharenko | NVIDIA | United Arab Emirates |
| Roderick Perez | OMV | Austria |
| Surender Manral | Schlumberger | Norway |
| Yohanes Nuwara | Aker BP | Norway |






